Job Design Pattern e best practice Talend: parte 1
Gli sviluppatori Talend di tutto il mondo, da quelli alle prime armi ai più esperti, spesso si pongono la stessa domanda: "Qual è il modo migliore per scrivere un job"? Sappiamo che i job devono essere efficienti, di facile lettura e scrittura e, soprattutto (nella maggior parte dei casi), di facile manutenzione. Sappiamo inoltre che Talend Studio è una "tela" bianca sulla quale "dipingiamo" il nostro codice utilizzando una tavolozza ricca e completa di componenti, oggetti repository, metadati e opzioni di collegamento. Come possiamo quindi essere sicuri di avere progettato un job utilizzando le best practice?
Job Design Pattern
Sin dalla versione 3.4, quando ho iniziato a usare Talend, la progettazione dei job è sempre stata molto importante per me. All'inizio, non pensavo ai pattern durante lo sviluppo dei miei job; avevo utilizzato Microsoft SSIS e altri strumenti simili prima, di conseguenza, un visual editor come Talend non era una novità per me. Al contrario, ero interamente concentrato sulle funzionalità di base, sulla riutilizzabilità del codice, sull'impostazione della "tela" e, per finire, sulle convenzioni di denominazione. Oggi, dopo aver sviluppato centinaia di job Talend per i casi d'uso più diversi, il mio codice è diventato più raffinato, più riutilizzabile, più coerente e i pattern hanno iniziato ad emergere.
Una volta entrato in Talend a gennaio di quest'anno, ho avuto moltissime opportunità di rivedere i job sviluppati dai nostri clienti. Ho potuto così confermare la mia percezione che ogni sviluppatore può trovare più soluzioni per ciascun caso d'uso. Questo, a mio parare, aggrava ulteriormente il problema per molti di noi. Noi sviluppatori tendiamo a pensare in modo simile, ma spesso siamo convinti che il nostro sia l'unico e il migliore modo possibile di sviluppare un particolare job. Anche se dentro di noi, sotto sotto, sappiamo che, forse, esiste un modo ancora migliore. E per questo motivo ci affidiamo alle best practice: in questo caso ai Job Design Pattern!
Formulazione degli elementi di base
Quando penso a cosa serve per creare il migliore codice possibile per un job, i precetti fondamentali non devono mai mancare. Essi sono il frutto di anni di esperienza, di errori e di miglioramenti. Rappresentano principi importanti che vanno a costituire una solida base su cui creare il codice e (a mio parare) devono essere sempre presi in seria considerazione. Secondo me, devono includere (senza alcun ordine di importanza):
– Leggibilità: creare codice facile da interpretare e da capire
– Scrivibilità: creare codice semplice, immediato, nel minor tempo possibile
– Sostenibilità: creare codice di complessità appropriata, che subisce minime conseguenze in caso di modifiche
– Funzionalità: creare codice che risponda ai requisiti
– Riutilizzabilità: creare oggetti condivisibili e unità di lavoro di dimensioni minime
– Conformità: creare uniformità e disciplina tra team, progetti, repository e codice
– Flessibilità: creare codice che si piega ma non si spezza
– Scalabilità: creare moduli elastici in grado di adattare la resa in base alle esigenze
– Coerenza: creare caratteristiche comuni a livello globale
– Efficienza: creare un flusso di dati e un utilizzo dei componenti ottimizzati
– Compartimentazione: creare moduli di dimensioni minime, finalizzati a un unico scopo
- Ottimizzazione: creare il massimo numero di funzionalità possibile con la minima quantità di codice
– Prestazioni: creare moduli efficaci che forniscono la massima resa nel minor tempo possibile
Ottenere un reale equilibrio tra questi precetti è fondamentale; in particolare, per quanto concerne i primi tre, in quanto sono in costante contraddizione tra loro. È possibile rispettarne due, sacrificando il terzo. Provate a metterli in ordine di importanza, se riuscite!
Linee guida, NON standard: è una questione di disciplina!
Prima di addentrarci nei Job Design Pattern, e unitamente ai precetti base appena illustrati, assicuriamoci di avere ben chiari alcuni dettagli aggiuntivi che dovrebbero essere presi in considerazione. Spesso mi trovo a fare i conti con standard che non lasciano spazio a situazioni inattese che spesso ne minano le basi. Oppure mi imbatto, sempre più spesso, nell'esatto opposto: codice rigido, trascurato e incongruo creato da sviluppatori diversi che puntano a ottenere fondamentalmente lo stesso risultato o, peggio ancora, sviluppatori che propagano una caotica e sconclusionata confusione. Onestamente, ritengo questo modo di procedere superficiale e fuorviante, in quanto non richiede particolare sforzo.
Per queste, così come per altre ovvie ragioni, preferisco creare e documentare delle linee guida anziché degli standard.
Queste devono includere i precetti fondamentali con eventuali specificità associate. Una volta creato un documento con le linee guida di sviluppo e adottato da tutti i team coinvolti nel ciclo vitale di sviluppo software (SDLC), i principi di base supporteranno struttura, definizione e contesto. Investendo in questo, nel lungo termine si potranno ottenere risultati di cui tutti saranno soddisfatti.
Ecco un quadro di riferimento che potete utilizzare per creare le vostre linee guida (si tratta di semplici spunti che potete modificare o ampliare secondo le vostre esigenze).
- Metodologie che dovrebbero descrivere nel dettaglio COME creare le linee guida
- Data Model
- Olistico/concettuale/logico/fisico
- Database, NoSQL, EDW, file
- Controlli del processo SDLC
- Waterfall o Agile/Scrum
- Requisiti e specifiche
- Gestione degli errori e audit
- Governance e stewardship dei dati
- Data Model
- Tecnologie che dovrebbero elencare gli STRUMENTI (interni ed esterni) e le loro correlazioni
- Topologia dell'infrastruttura e del sistema operativo
- Sistemi di gestione del database
- Sistemi NoSQL
- Crittografia e compressione
- Integrazione di software di terze parti
- Interfacce dei servizi web
- Interfacce dei servizi esterni
- Best practice che dovrebbero descrivere CHE COSA devono includere e QUANDO devono essere adottate particolari linee guida
- Ambienti (DEV/QA/UAT/PROD)
- Convenzioni di denominazione
- Progetti, job e joblet
- Oggetti repository
- Registrazione, monitoraggio e notifiche
- Codici di restituzione dei job
- Routine dei codici (Java)
- Gruppi di contesto e variabili globali
- Database e connessioni NoSQL
- Dati sorgente/destinazione e schemi di file
- Punti di ingresso e uscita dei job
- Workflow e layout dei job
- Utilizzo dei componenti
- Parallelizzazione
- Qualità dei dati
- Job e joblet padre/figlio
- Protocolli di scambio dati
- Implementazione e integrazione continue
- Controllo del codice sorgente integrato (SVN/GIT)
- Controllo e gestione delle versioni
- Test automatizzati
- Repository e promozione degli artefatti
- Amministrazione e attività
- Configurazione
- Sicurezza utenti e autorizzazioni
- Ruoli e autorizzazioni
- Gestione progetti
- Attività, pianificazioni e trigger dei job
- Archivi e disaster recovery
Tra i documenti aggiuntivi che a mio parare dovrebbero essere sviluppati e regolarmente aggiornati vi sono:
– Libreria moduli: con la descrizione di tutti i progetti, metodi, oggetti, joblet e gruppi di contesto riutilizzabili
– Dizionario dati: con la descrizione di tutti gli schemi di dati e le procedure memorizzate correlate
– Layer di accesso ai dati: con la descrizione di tutto quanto concerne la connessione e la manipolazione dei dati
Sicuramente, creare una simile documentazione richiede tempo, tuttavia, il suo valore, durante la sua intera vita utile, ne compensa ampiamente i costi. Mantenete tale documentazione il più possibile semplice, diretta e aggiornata (non deve essere un manifesto) e vedrete che farà un'enorme differenza nei progetti in cui viene utilizzata, riducendo drasticamente gli errori di sviluppo (che possono rivelarsi estremamente costosi).
Possiamo passare ai Job Design Pattern adesso?
Certo! Ma prima, ancora una cosa. Sono convinto che ogni sviluppatore possa adottare buone e cattive abitudini durante la scrittura di codice. Potenziare le buone abitudini è fondamentale. Si può iniziare da qualcosa di molto semplice, come assegnare sempre un'etichetta a ogni componente. Questo renderà il codice più leggibile e comprensibile (secondo uno dei nostri precetti fondamentali). Una volta che tutti hanno sviluppato questa abitudine, assicuratevi che i job vengano scrupolosamente organizzati in cartelle repository con nomi significativi che abbiano un senso per i progetti a cui sono destinati (esatto, stiamo parlando di conformità). Quindi, fate in modo che tutti adottino lo stesso stile di messaggi di registrazione, magari utilizzando un method wrapper comune attorno alla funzione System.out.PrintLn(), e stabilite un criterio comune per i punti di ingresso/uscita, con opzioni per requisiti alternativi, per codice job (entrambe queste abitudini aiutano a rispettare più precetti simultaneamente). Nel corso del tempo, a mano a mano che i team di sviluppo adotteranno e utilizzeranno linee guida ben definite, il codice dei progetti diventerà più facile da leggere, scrivere e (il mio preferito) aggiornare da chiunque nel team.
Job Design Pattern e best practice
I Job Design Pattern di Talend offrono una proposta di modello o uno schema di impostazione che include elementi essenziali e/o obbligatori, incentrati su particolari casi d'uso. Si definiscono pattern perché spesso possono essere riutilizzati per la creazione di job simili, riducendo il lavoro di sviluppo del codice. Come ci si può aspettare, vi sono anche pattern di uso comune che possono essere adottati in molti casi d'uso differenti che, se identificati e implementati correttamente, consentono di rafforzare la base del codice in generale, condensare lo sforzo e ridurre il codice ripetitivo ma simile. Cominciamo dunque da qui.
Ecco 7 best practice da tenere in considerazione:
Workflow e layout della "tela"
Esistono tanti modi di distribuire i componenti sulla "tela" del job e altrettanti per collegarli tra loro. Il mio metodo preferito consiste fondamentalmente nel procedere dall'alto verso il basso, quindi a sinistra e a destra, considerando che un flusso verso sinistra corrisponde generalmente a un percorso errato, mentre un flusso diretto verso destra e/o verso il basso corrisponde al percorso desiderato o normale. Evitare, ove possibile, linee di collegamento che si intersecano è buona norma e nella versione 6.0.1 questa strategia viene adottata alla perfezione mediante l'utilizzo di collegamenti curvi.
Per quanto mi riguarda, mi trovo bene con il pattern a zig-zag, in cui i componenti vengono posizionati in serie da sinistra a destra, quindi, quando si raggiunge il limite destro, il componente successivo viene posizionato in basso in corrispondenza del bordo sinistro; riconosco che questo pattern sia un po' confuso e di difficile manutenzione, ma a me risulta facile da scrivere. Usate questo pattern se dovete, ma tenete presente che può indicare che il job faccia più del dovuto o che non sia organizzato correttamente.
Moduli job di dimensioni minime – Job padre/figlio
Job enormi, con grandi quantità di componenti sono difficili da comprendere e da gestire. Per evitare questo problema, è possibile suddividerli in job o moduli di lavoro più piccoli, quindi eseguirli come job figli a partire da un job padre (utilizzando il componente tRunJob), il cui scopo include il loro controllo e la loro esecuzione. In questo modo si crea anche l'opportunità di gestire meglio gli errori e ciò che accade dopo. Job disordinati possono risultare difficili da comprendere, complicati da correggere e la loro manutenzione può diventare quasi impossibile. Job semplici e di piccole dimensioni, con una finalità chiara, sono sempre più facili da correggere in caso di errori e anche la loro manutenzione risulta più immediata.
Nonostante sia perfettamente accettabile creare gerarchie padre/figlio di job nidificati, vi sono alcuni limiti pratici da considerare. In base all'utilizzo di memoria del job, ai parametri trasmessi, a problemi di test/debugging e alle tecniche di parallelizzazione (descritte di seguito), un buon Job Design Pattern non dovrebbe superare i 3 livelli di chiamate tRunJob padre/figlio. Anche se andare più in profondità non costituisce un problema, ritengo che cinque livelli siano più che sufficienti per un qualsiasi caso d'uso.
tRunJob e joblet
La differenza tra l'utilizzo di un job figlio e di un joblet consiste nel fatto che il job figlio viene chiamato a partire dal job, mentre il joblet viene incluso nel job stesso. Entrambi offrono l'opportunità di creare moduli di codice riutilizzabili e/o generici. Una strategia molto efficace in qualunque Job Design Pattern consiste nell'incorporare in modo corretto il loro uso.
Punti di ingresso e di uscita
Tutti i job Talend devono iniziare e terminare in un punto. Talend offre due componenti di base: tPreJob e tPostJob la cui finalità consiste nell'aiutare a controllare ciò che accade prima e dopo che il contenuto di un job viene eseguito. Considero questi due componenti come i passaggi di inizializzazione e conclusione del mio codice. Si comportano esattamente come il loro nome suggerisce, in quanto in prima istanza viene eseguito tPreJob, quindi viene eseguito il codice vero e proprio, infine viene eseguito tPostJob. Il codice tPostJob viene eseguito a prescindere da qualsiasi uscita predisposta all'interno del corpo del codice (come un componente tDie o un'opzione "die on error" del componente).
Anche l'uso dei componenti tWarn e tDie dovrebbe essere preso in considerazione per i punti di ingresso e di uscita dei job. Tali componenti offrono un controllo programmabile su dove e come un job deve essere portato a termine. Supportano inoltre opportunità di gestione degli errori, registrazione e recovery ottimizzate.
In un Job Design Pattern come questo utilizzo il componente tPreJob per inizializzare le variabili di contesto, stabilire le connessioni e inserire in registro informazioni importanti. Mentre utilizzo tPostJob per chiudere le connessioni, eseguire altre importanti azioni di pulizia e inserire ulteriori informazioni nel registro. Semplice, non è vero? Fate così anche voi?
Registrazione e gestione degli errori
Questo è un aspetto estremamente importante: se si riesce a creare correttamente un Job Design Pattern comune, è possibile stabilire un meccanismo riutilizzabile in quasi tutti i progetti. Il mio pattern prevede la creazione di un joblet logPROCESSING per un processore di registrazione coerente e di facile manutenzione che può essere incluso in qualsiasi job, OLTRE all'incorporazione di codici di restituzione ben definiti che garantiscono conformità, riutilizzabilità ed elevata efficienza. In più è estremamente facile da scrivere, da leggere e da manutenere. A mio parere, è fondamentale sviluppare un proprio modo di gestire e registrare gli errori in tutti i job dei progetti. La regola è adattarsi e mettere in pratica!
In versioni recenti di Talend è stato aggiunto il supporto di Log4j e di un server di registro. Basta semplicemente abilitare l'opzione di menu Project Settings (Impostazioni progetto) > Log4j e configurare il server Log Stash in TAC. Incorporare questa funzionalità di base nei job è sicuramente un'ottima pratica.
Link dei componenti OnSubJobOK/ERROR e OnComponentOK/ERROR (e Run If)
Per gli sviluppatori Talend talvolta può risultare difficile capire le differenze tra i link On SubJob e On Component. La differenza tra OK ed ERROR è ovvia. Quali sono quindi le differenze tra queste connessioni trigger e come influenzano il flusso di progettazione di un job?
Le connessioni trigger tra i componenti definiscono la sequenza di elaborazione e il flusso di dati in cui esistono dipendenze tra componenti all'interno di un sotto-job. I sotto-job sono caratterizzati da un componente che presenta uno o più componenti a esso collegati e che hanno a che fare con il flusso di dati corrente. All'interno di un singolo job possono esistere più sotto-job, visualizzati per impostazione predefinita mediante una casella blu evidenziata (attivabile/disattivabile dalla barra degli strumenti) che racchiude tutti i componenti del relativo sotto-job.
Un trigger On Subjob OK/ERROR porterà avanti il processo fino al successivo sotto-job collegato, una volta che tutti i componenti all'interno del sotto-job avranno completato l'elaborazione. Questo procedimento dovrebbe partire dal componente iniziale del sotto-job. Un trigger On Component OK/ERROR porterà avanti il processo fino al successivo componente collegato, una volta che tale componente avrà completato l'elaborazione. Un trigger Run If può risultare utile quando la continuazione del processo al successivo componente collegato si basa su un'espressione java programmabile.
Che cos'è il loop di un job?
In quasi tutti i Job Design Pattern hanno un ruolo significativo il loop principale ed eventuali loop secondari del codice. Si tratta dei punti in cui viene esercitato il controllo della potenziale uscita di un job in esecuzione. Il loop principale è generalmente rappresentato dalla fase di elaborazione più alta di un set di risultati di un flusso di dati che, una volta completata, determina la conclusione del job. I loop secondari sono nidificati all'interno di un loop di ordine superiore e spesso richiedono considerevole controllo per garantire l'uscita corretta dei job. Io identifico sempre il loop principale e mi assicuro di aggiungere un componente tWarn e tDie al componente di controllo. Il componente tDie viene generalmente impostato per uscire immediatamente da JVM (si noti che anche in questo caso il codice tPostJob verrà comunque eseguito). Questi punti di uscita di livello alto impiegano un semplice codice di restituzione 0 per indicare la riuscita e 1 per indicare l'errore, ma è comunque consigliabile seguire le linee guida stabilite per i codici di restituzione. I loop secondari (e altri componenti critici del flusso) sono ottimi punti in cui incorporare componenti tWarn e tDie aggiuntivi (se tDie NON è impostato per uscire immediatamente da JVM).
La maggior parte delle best practice e dei Job Design Pattern di cui abbiamo discusso è illustrata di seguito. Come si può notare, ho utilizzato utili etichette per i componenti, anche se ho leggermente cambiato le regole a livello di posizionamento dei componenti. Ciononostante, ho ottenuto un job molto leggibile e di facile manutenzione che è risultato abbastanza semplice da scrivere.
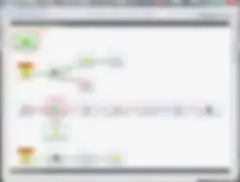
Conclusione
Sicuramente, molte delle vostre domande sui Job Design Pattern non avranno trovato una risposta nei contenuti di questo blog. Ma è comunque un inizio! Abbiamo coperto alcuni aspetti fondamentali, offrendo una direzione da seguire e un finale di partita. Mi auguro che questa presentazione vi sia stata utile e abbia suscitato in voi proficue considerazioni.
È chiaro che dovrò scrivere un altro blog (o magari anche più di uno) per coprire l'intero argomento. Il prossimo sarà incentrato su alcuni utili approfondimenti e su diversi casi d'uso in cui potremmo imbatterci. Inoltre, il team Customer Success Architecture sta lavorando alla creazione di codice Talend di esempio a supporto di tali casi d'uso. Tale codice sarà presto disponibile nel Centro assistenza Talend per i clienti abbonati. State all'erta.
Risorse correlate
5 modi per diventare protagonisti dell'integrazione dei dati
Prodotti menzionati

Altri articoli correlati
- "Job Design Pattern e best practice Talend": Parte 4
- "Job Design Pattern e best practice Talend": Parte 3
- Che cos'è la migrazione dei dati?
- Che cos'è la mappatura dei dati?
- Che cos'è la Data Integration?
- Migrazione dei dati: strategia e best practice
- Job Design Pattern e best practice Talend: parte 2
- Change Data Capture (CDC)
- Guida per sviluppatori alla migrazione da Informatica PowerCenter a Talend: Parte 1